了解自编码器(Autoencoder)和其用于异常检测的原理
首先,用花书第14章的原文介绍一下自编码器:
自编码器是一种神经网络,经过训练后,能尝试将输入复制到输出。
自编码器内部有一个隐藏层h,可以产生编码(code)用于输入。
该网络可以看做两部分组成:一个由函数表示的编码器和一个生成重构的解码器
如果一个自编码器只是简单地学会,那么这个自编码器就没什么特别的用处。
相反,不应该将自编码器设计成输入和输出完全相等。通常需要向自编码器加一些约束,使其只能近似复制,并只能复制与训练数据相似的输入。
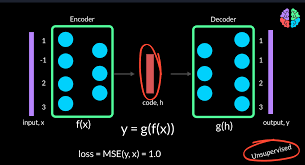
使用自编码器,如何用于异常检测?假如有一组已知是正常的数据,用这些数据训练模型,用训练好的模型判断未知的数据是否异常。原理是:自编码器是无监督学习模型,从输入数据中提取特征并将其压缩到一个潜在空间,再从这个潜在空间重建输入数据。对于正常数据,自编码器应该能够很好地重建输入数据;而对于异常数据,由于自编码器没有在训练时见过这些数据,重建误差通常会较大,因此可以用这个重建误差来判断数据是否异常。
好的,所以看到这里有几个问题:怎么压缩的?怎么重建的?重建就是预测吗?潜在空间是什么?
自编码器的模型类型
- 基本自编码器:这是最基础的模型,由一个编码器和一个解码器组成。编码器将输入数据压缩成一个低维表示,解码器则从这个低维表示重建原始数据。此外,还有变分、卷积、稀疏自编码器,本此不深入学习。
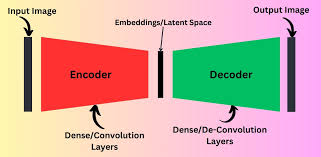
自编码器用于异常检测的构建步骤
- 预处理:标准化或归一化、降维(比如 PCA)。
- 构建自编码器模型:可以用深度学习框架构建模型,选择损失函数,比如用均方误差 MSE(Mean Squared Error)。
- 训练模型:用正常数据训练模型,监控重建误差
- 设定异常检测阈值:使用训练数据或验证数据计算重建误差的分布。设定一个阈值,通常是根据重建误差的均值加上若干倍的标准差(如 3 倍标准差)。
- 检测未知数据:使用训练好的自编码器对未知数据进行重建,计算重建误差。如果误差超过设定的阈值,则认为数据是异常的。
关于损失函数:用于衡量模型预测结果与实际目标值之间的差异。模型的目标是通过不断调整内部参数(如权重和偏置)来最小化损失函数的值,从而提高预测的准确性。在自编码器中,损失函数用于衡量输入数据和重建数据之间的差异。自编码器的训练目标是使这个差异最小化,以便模型能够很好地重建输入数据。比如上面提到的均方误差,公式如下,其中是观测值(实际值),是预测值。
损失的衡量:对于一个自编码器,我输入了原始数据,和经过编码解码的重建数据。假如使用均方误差作为损失函数,我计算出输入和重建数据的均方误差。但是这个损失值计算出来之后,我怎么知道他小不小,这个大小怎么衡量呢?主要参考几个方面:
- 在训练过程中的相对比较:在训练的早期,损失值通常较大。随着训练的进行,损失值应该逐渐减小。因此,通过观察损失值随训练轮次的变化趋势,可以判断模型的收敛情况。损失值的持续下降表明模型在逐步学习并改善。
- 与基线比较:在训练开始时,使用随机初始化的模型计算的初始损失值可以作为一个基线。之后的损失值越小,表明模型表现越好。
- 与数据范围比较:如果对数据的范围已经有了一定的了解,可以将损失值与这个范围进行比较。例如,如果输入数据已经标准化到一个范围(如 0 到 1),那么均方误差的期望值一般也会比较小。如果损失值远大于这个范围,说明模型在重建输入数据时出现了较大的误差。
- 绝对阈值:可以设定一个绝对阈值来判断损失值是否足够小。这个阈值可以根据实际应用场景和数据特性来定。例如,假设你认为一个均方误差小于 0.01 的模型在你的任务中表现已经很好,那么这个阈值可以作为你衡量损失大小的标准。
- 在验证集上的表现:如果有验证集,可以在验证集上计算损失值。如果验证集上的损失值较小且稳定,那么模型的重建能力一般是可以接受的。
- 实际应用效果:在一些实际应用中,你可以直接观察模型在检测异常数据时的表现。如果模型能够有效区分正常数据和异常数据,并且损失值对异常数据有显著区分度(即对于异常数据,损失值明显较大),那么可以认为这个损失值足够好。
例子
假设有一份 N 行(N 个样本)M 列(M 个特征)的数据,表示该数据结构的变量为 Data。用这段数据构建一个只有一个编码器和一个解码器的自编码模型。
import pandas as pd
import numpy as np
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
df = pd.read_csv('data.csv') # 导入CSV文件
df['Gender'] = df['Gender'].map({'Female': 0, 'Male': 1})
le = LabelEncoder()
df['Course'] = le.fit_transform(df['Course'])
df['YearOfStudy'] = le.fit_transform(df['YearOfStudy'])
df_numeric = df.select_dtypes(include=['number'])
scaler = MinMaxScaler()
df_normalized = pd.DataFrame(scaler.fit_transform(df_numeric), columns=df_numeric.columns)
Data = df_normalized.values # 转成numpy数组Data,大小是N行*M列
# 构建自编码器模型:输入、编码器和解码器
input_layer = Input(shape=(Data.shape[1],)) # 定义输入层的形状,Data.shape[1] 表示列数,输入数据的特征数为 M
encoded = Dense(10, activation='relu')(input_layer) # 编码器层,压缩数据到一个较小的潜在空间,比如设置10个神经元,制定relu为激活函数。
decoded = Dense(Data.shape[1], activation='sigmoid')(encoded) # 解码器层,重建数据到原始特征数,输出层,特征数为 M
# 定义自编码器模型
autoencoder = Model(inputs=input_layer, outputs=decoded)
# 设置模型,Adam作为优化器,均方误差作为损失函数
autoencoder.compile(optimizer=Adam(), loss='mean_squared_error')
# 训练模型
autoencoder.fit(Data, Data, epochs=50, batch_size=32, shuffle=True, validation_split=0.1)
# 使用模型进行重建
reconstructed_data = autoencoder.predict(Data)
mse_per_sample = np.mean((Data - reconstructed_data)**2, axis=1)
threshold = np.percentile(mse_per_sample, 95)
is_anomaly = mse_per_sample > threshold
用Dense层构建编码器、解码器:Dense 在神经网络中,这是一个全连接层。它将输入数据与一组权重(weight)进行线性运算,会加上一个偏置项。
compile函数用于设置模型的优化器和损失函数。
fit 函数用于训练模型。这个函数的参数是输入数据和目标数据,并通过优化过程来调整模型的参数,以最小化损失函数。
为什么编码器通常需要比输入维度少的神经元?
自编码器的目标是压缩输入数据,如果编码器的神经元数与输入维度相同或更多,那么自编码器就没有实际的压缩过程。它会变成一个简单的恒等映射,直接将输入复制到输出,而没有真正的学习或压缩。
训练数据重建误差的 95th 怎么理解
95th 百分位数:这个值表示训练数据中 95% 的样本的重建误差都低于这个阈值,只有 5% 的样本的重建误差高于这个值。在异常检测中,这意味着重建误差高于 95th 百分位数的样本被认为是异常的。